Edge AI – Resource-efficient hardware for artificial intelligence
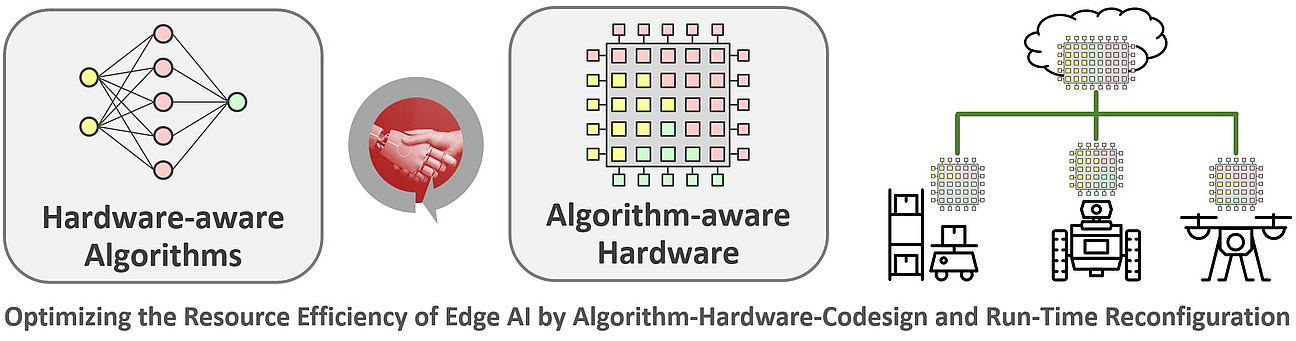
Edge AI transfers machine learning from the cloud to end devices or even directly into the sensor-actuator systems to enable real-time decisions and to meet important privacy and security requirements. This is essential for applications in the areas of autonomous driving, Industry 4.0, and smart homes. Hardware-software platforms for edge computing are subject to strong resource constraints, and applications usually have to compromise on the accuracy of calculations. Therefore, we focus on scalable heterogeneous hardware that combines domain-specific architectures with GPUs and FPGAs. Whenever advantageous, our systems can even change their hardware architecture at run-time. This allows them to adapt to new requirements and, for example, optimize power dissipation, performance, or quality of results.
Resource-efficient hardware architectures for machine learning
In our research, we explore new architectural concepts for resource-efficient implementation of AI algorithms that are particularly suitable for use in mobile, energy-constrained systems. While the training of neural networks is usually based on floating-point representations, which can be processed most efficiently by GPUs or dedicated TPUs, quantization is the key to increasing energy efficiency for inference. We focus on a codesign approach that is based on a holistic optimization of hardware architectures and ML algorithms. The basis for the codesign is our flexible architecture generator STANN, which can be parameterized with respect to the realized computing units as well as the internal precision. In addition to the classic parameters of energy and resource requirements, performance, and accuracy, interpretability is becoming an important additional optimization goal.
Research projects and examples of applications
- HybrInt – Hybrid Intelligence through Interpretable AI in Machine Perception and Interaction
In Hybrint, we explore new approaches for the resource-efficient realization of accelerators for deep reinforcement learning and interpretable AI models. The targeted applications focus on autonomous machines for agriculture. - VEDLIoT – Very Efficient Deep Learning in IoT
In this EU-funded project, we collaborated with eleven international partners on new methods and applications for highly efficient deep learning models in the Internet of Things. Our aim in this area is to further optimize resource efficiency for AI applications by increasing performance while minimizing energy requirements through the use of dedicated hardware accelerators. - Real-Time DC Series Arc Fault Detection
Based on our implementations in VEDLIoT, we are developing new architectures for the real-time detection of arcs in DC power systems with deep learning models in collaboration with Siemens. We Here, we focus on FPGA-based accelerators created with our architecture generator STANN. - Joint Lab Artificial Intelligence & Data Science
The working group is involved in the joint research training group with two projects focusing on „Simulation of Environment Sensors – towards digital twins of autonomous agricultural machines“, and „Reconfigurable ROS Nodes for Modular Agricultural Robots“.
Selected Publications
- Li, Y.; Rothmann, M.; Porrmann, M.:
Resource-Efficient Implementation of Convolutional Neural Networks on FPGAs with STANN.
In: 18th International Work-Conference on Artificial Neural Networks, IWANN 2025, A Coruña, Spain, 16-18 June, 2025, pp. 179-191.
DOI: https://doi.org/10.1007/978-3-032-02725-2_14 - Li, Y.; Mao, Y.; Weiss, R.; Rothmann, M.; Porrmann, M.:
High-Performance FPGA-Based CNN Acceleration for Real-Time DC Arc Fault Detection.
In: 18th International Work-Conference on Artificial Neural Networks, IWANN 2025, A Coruña, Spain, 16-18 June, 2025, pp. 192-204.
DOI: https://doi.org/10.1007/978-3-032-02725-2_15 - Mao, Y.; Weiss, R.; Zhang, Y.; Li, Y; Rothmann, M.; Porrmann, M.:
FPGA Acceleration of DL-Based Real-Time DC Series Arc Fault Detection.
31st Reconfigurable Architectures Workshop, RAW 2024, San Francisco, CA, USA, May 27th-28th 2024, pp.92-98.
DOI: doi.org/10.1109/IPDPSW63119.2024.00031 - Rothmann, M.; Porrmann, M.:
FPGA-based Acceleration of Deep Q-Networks with STANN-RL.
In: 9th IEEE International Conference on Fog and Mobile Edge Computing, FMEC 2024, Malmö, Sweden. September 2-5, 2024, pp. 99-106.
DOI: doi.org/10.1109/FMEC62297.2024.10710277 - Porrmann, F.; Hagemeyer, J.; Porrmann, M.:
HLS-based Large Scale Self-Organizing Feature Maps.
In IEEE Access, Vol. 12, 2024.
DOI: doi.org/10.1109/ACCESS.2024.3471471 - Griessl, R.; Porrmann, F.; Kucza, N.; Mika, K.; Hagemeyer, J.; Kaiser, M.; Porrmann, M.; Tassemeier, M.; Flottmann, M.; Qararyah, F.; Waqar, M.; Trancoso, P.; Ödman, D.; Gugala, K.; Latosinski, G.:
A Scalable, Heterogeneous Hardware Platform for Accelerated AIoT based on Microservers.
In Sofia, R. C. and Soldatos, J. (Eds.), Shaping the Future of IoT with Edge Intelligence, pp. 179-196, River Publishers, 2024, ISBN 978-1-032-63240-7,
DOI: doi.org/10.1201/9781032632407-11 - Rothmann, M.; Porrmann, M.:
STANN – Synthesis Templates for Artificial Neural Network Inference and Training.
In: 17th International Work-Conference on Artificial Neural Networks, IWANN 2023, Ponta Delgada, Azores, Portugal, June 19-21, 2023, pp. 394–405.
DOI: doi.org/10.1007/978-3-031-43085-5_31 - Tassemeier, M.; Porrmann, M.; Griessl, R.; Hagemeyer, J.; Trancoso, P.:
Reconfigurable Accelerators for Heterogenous Computing in AIoT (Extended Abstract).
In: 17th International Work-Conference on Artificial Neural Networks, IWANN 2023, Ponta Delgada, Azores, Portugal, June 19-21, 2023. - Mika, K.; Griessl, R.; …; Tassemeier, M.; Porrmann, M. et al.:
VEDLIoT – Next generation accelerated AIoT systems and applications (Invited Paper).
In: 20th ACM Int. Conference on Computing Frontiers, Bologna, Emilia-Romagna, Italy, May 9-11, 2023.
DOI: doi.org/10.1145/3587135.3592175 - Griessl, R.; Porrmann, F.; Kucza, N.; Mika, K.; Hagemeyer, J.; Kaiser, M.; Porrmann, M.; Tassemeier, M.; Flottmann, M.; Qararyah, F.; Waqar, M.; Trancoso, P.; Ödman, D.; Gugala, K.; Latosinski, G.:
Evaluation of heterogeneous AIoT Accelerators within VEDLIoT.
In: Design, Automation and Test in Europe Conference (DATE 23), Antwerp, Belgium, April 17-19, 2023.
DOI: doi.org/10.23919/DATE56975.2023.10137021 - Zhang, S.; Wallscheid, O.; Porrmann, M.:
Machine Learning for the Control and Monitoring of Electric Machine Drives: Advances and Trends.
In: IEEE Open Journal of Industry Applications, Vol. 4, pp. 188-214, 2023,
DOI: doi.org/10.1109/OJIA.2023.3284717 - Rothmann, M.; Porrmann, M.:
A Survey of Domain-Specific Architectures for Reinforcement Learning.
In: IEEE Access, vol. 10, pp. 13753-13767, 2022,
DOI: doi.org/10.1109/ACCESS.2022.3146518 - FAQ: A Flexible Accelerator for Q-Learning with Configurable Environment.
In: 33rd IEEE International Conference on Application-specific Systems, Architectures and Processors (ASAP 2022), pp. 106-114, Gothenburg, Sweden, July 12-14, 2022.
DOI: doi.org/10.1109/ASAP54787.2022.00026 - Kaiser, M.; Griessl, R.; ...; Porrmann, M.; Tassemeier, M. et al.:
VEDLIoT: Very Efficient Deep Learning in IoT.
In: Design, Automation and Test in Europe Conference (DATE 22), Antwerp, Belgium, March 14-23, 2022.
DOI: doi.org/10.23919/DATE54114.2022.9774653